Supervisor Architectures for Multi-Agent Systems: Unifying Independent Agents Without the Chaos
Published 2026-06-05 · ~18 min read · Agentic Systems / Distributed Systems
There is a predictable moment in the life of every organization that adopts LLM agents. It starts well: one team ships an agent that answers questions about delivery routes. Another ships one that summarizes labor metrics. A third wraps a forecasting model. Each is useful in isolation, each has its own deployment, its own prompt, its own set of tools.
Then a user asks a question that touches two of them, “Why is station X behind on its plan today?”, and the cracks show. One agent says the cause is volume. Another says it’s headcount. They are both reading from the same underlying data, but they reach conflicting conclusions, because nothing coordinates them. They don’t share state, they don’t share a definition of “today,” and they each made an independent tool call that returned a slightly different slice of reality.
This is the problem a supervisor architecture exists to solve. It is the single most important structural decision you will make when you go from “we have some agents” to “we have an agent platform.” This article is a deep, practical treatment of that pattern: what it is, why it beats the alternatives, how to handle routing, state, tool collisions, and failure, and where it will bite you.
1. The shape of the problem
Start by naming what actually goes wrong when independently built agents coexist without coordination. There are four failure modes, and they compound.
1. Conflicting decisions. Two agents reason over overlapping domains and emit contradictory answers. There is no arbiter, so the user, or worse, a downstream automated system, has to reconcile them.
2. Duplicated tool logic. Agent A and Agent B both need to query the orders service. They each implement their own client, their own retry logic, their own notion of pagination. The clients drift. One handles a schema change, the other silently returns stale fields.
3. No shared context. A user’s question is a conversation, not a single turn. When the routing layer hands turn 1 to Agent A and turn 2 to Agent B, the second agent has no idea what “it” refers to. Memory is fragmented across agents that never talk.
4. Unobservable behavior. When something is wrong, you cannot answer the question “which agent did what, in what order, and why?” because there is no single trace. Each agent logs into its own corner.
The instinct is to fix these one at a time, share a tool library here, add a session store there. But the failures are symptoms of one missing thing: there is no component that owns the request end-to-end. That component is the supervisor.
2. What a supervisor actually is
A supervisor is an agent whose tools are other agents. Instead of calling
get_orders() or query_metrics(), it calls route_to(routing_agent) or
delegate(forecasting_agent, subtask). It holds the plan, decides who does what,
maintains the authoritative state for the request, and synthesizes a single answer.
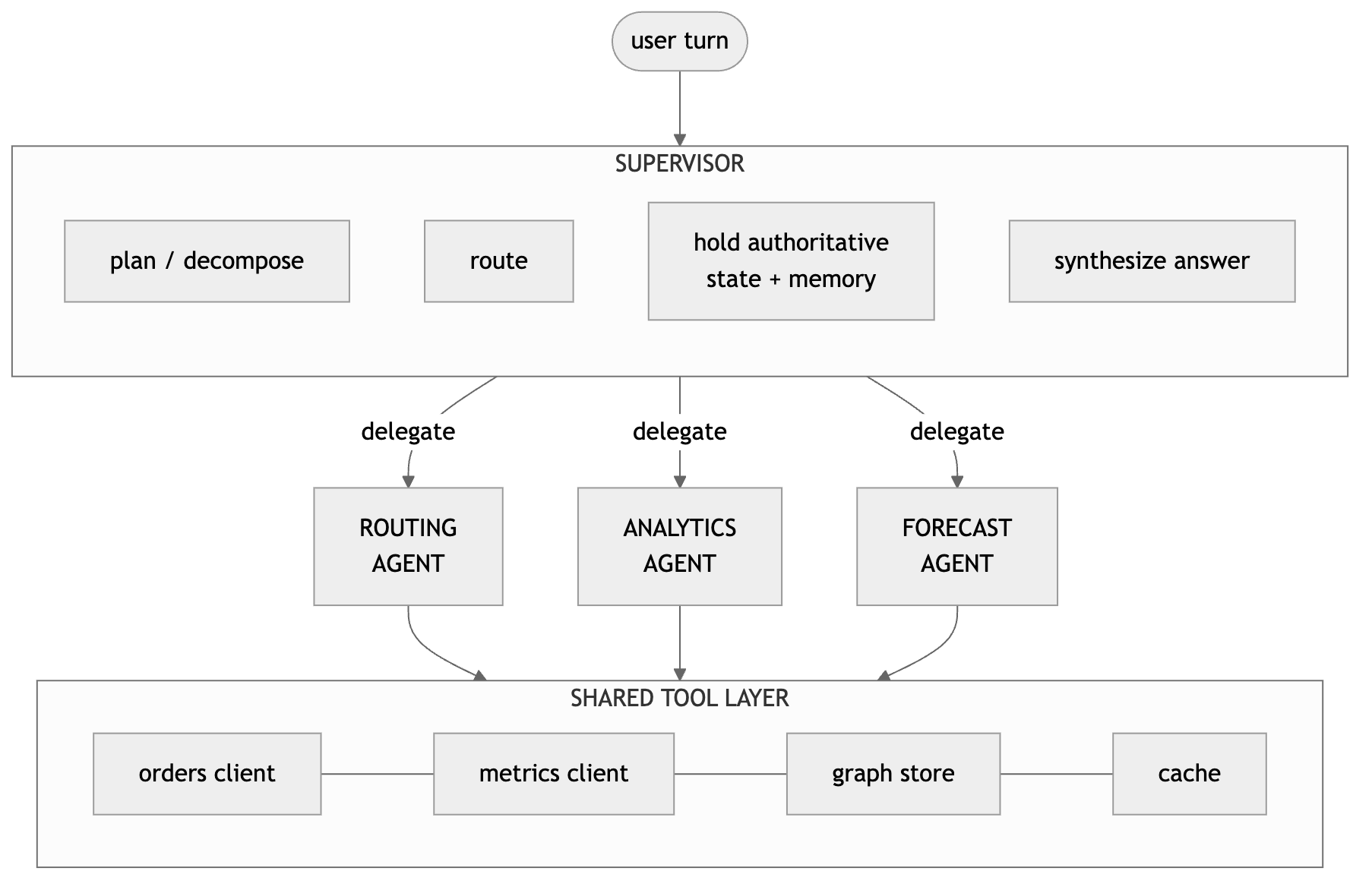
The key inversion: agents stop being peers and become workers. A worker agent no longer decides whether it should answer a question, it answers the subtask it was given. The decision of “who answers” moves up one level, to a component that can see the whole request.
This is not novel. It is the same idea as a coordinator in a distributed
transaction, a load balancer’s L7 router, or a Makefile that knows the dependency
graph. What is new is that the coordinator is itself probabilistic, which changes
how you reason about correctness.
3. Routing: the part everyone overcomplicates
The first thing the supervisor does with an incoming turn is decide where it goes. The naive implementation hands the entire decision to an LLM: “Here are five agents and their descriptions. Which one should handle this?” This works in a demo and fails in production for three reasons: it adds 2–15 seconds of latency to every turn, it is non-deterministic, and it is the hardest part of the system to debug when it’s wrong.
The discipline worth internalizing: routing, classification, and validation do not require language understanding. Reserve model inference for steps that genuinely need reasoning. A tiered router gets you most of the way for a fraction of the cost:
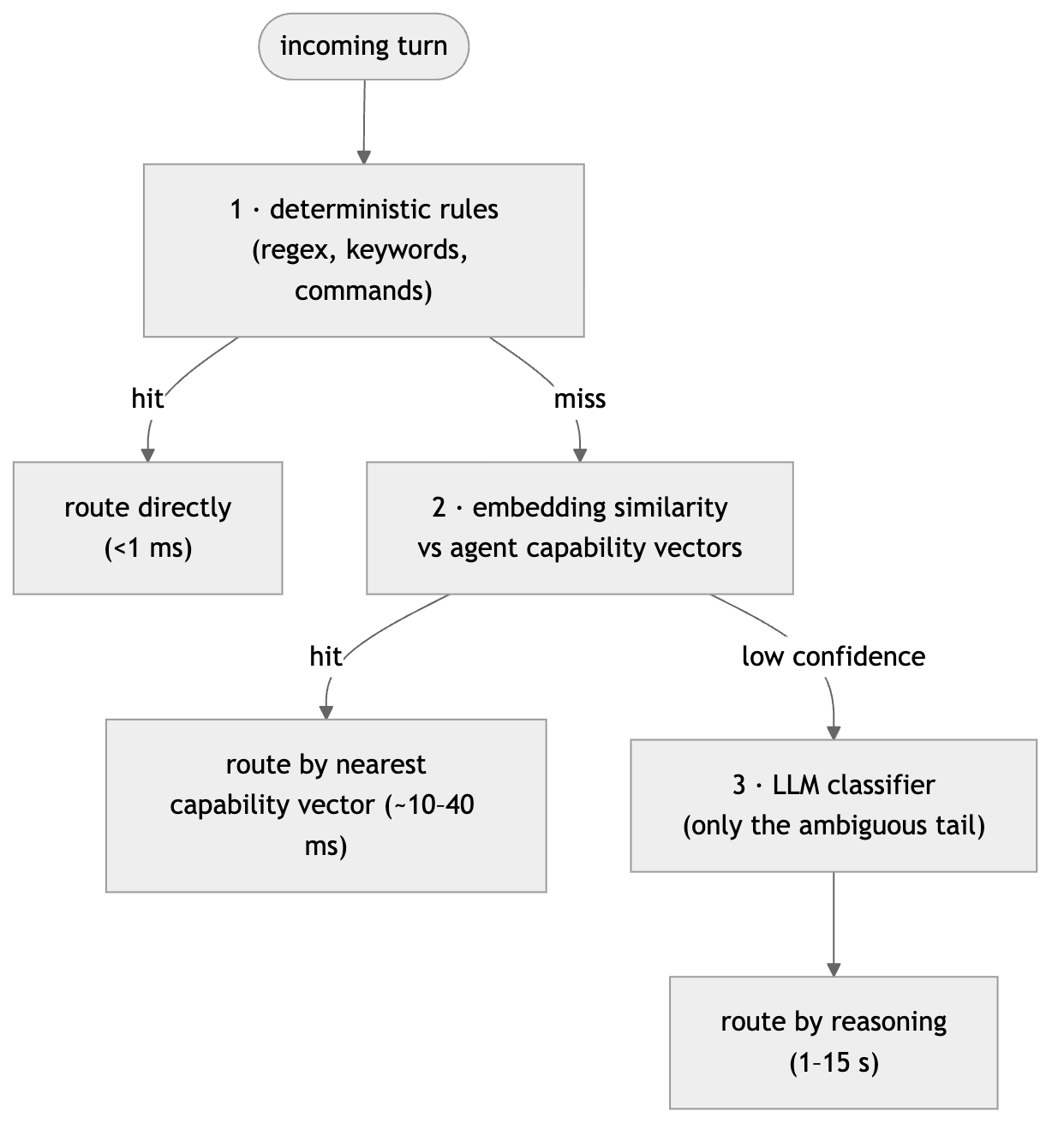
In practice the top tier absorbs a large share of traffic. Commands, well-known phrasings, and structured inputs never need a model. The embedding tier catches paraphrases. Only the genuinely ambiguous tail, the questions that span domains, reaches the LLM classifier, and that is exactly the place where a supervisor’s reasoning earns its cost.
A subtle but important rule: the router should be allowed to choose more than one agent, or none. A question like “compare forecasted vs actual volume and tell me if staffing was the cause” legitimately needs the analytics agent and the forecast agent, then a synthesis step. If your router is a single-label classifier, you have quietly assumed every question maps to exactly one domain, and the cross-domain questions are precisely the ones that motivated the supervisor in the first place.
4. State: the supervisor owns the truth
The defining property of a supervisor is that it holds the authoritative state for a request. Worker agents are given a scoped, read-mostly view and return deltas. They do not mutate global state directly. This is the same principle as a single-writer log: concurrency is safe because there is exactly one component allowed to commit.
Model the state as an explicit, typed object, not an untyped dict that every agent pokes at:
from dataclasses import dataclass, field
from datetime import date
from enum import Enum
class TurnStatus(str, Enum):
ROUTING = "routing"
DELEGATED = "delegated"
SYNTHESIS = "synthesis"
DONE = "done"
FAILED = "failed"
@dataclass
class RequestState:
request_id: str
session_id: str
user_query: str
# Resolved ONCE by the supervisor, shared by every worker.
as_of: date
site_id: str
status: TurnStatus = TurnStatus.ROUTING
# Append-only record of what each worker returned.
contributions: list["Contribution"] = field(default_factory=list)
# Conversation memory, carried across turns.
history: list[dict] = field(default_factory=list)
@dataclass
class Contribution:
agent: str
subtask: str
result: dict
tool_calls: list[dict] # for traceability
confidence: float
Two design choices here matter more than they look.
Resolve shared parameters once. as_of (what “today” means) and site_id are
resolved by the supervisor before delegation and passed down. This single decision
eliminates an entire class of “conflicting answer” bugs, because two agents can no
longer disagree about the date or the scope. If you let each agent resolve “today”
independently, one will use ingestion time, another processing time, and they will
diverge on exactly the late-arriving-data boundaries that matter most.
Contributions are append-only. Workers append results; they never overwrite. The supervisor reads the full set during synthesis and can detect contradictions explicitly, “forecast says staffing-bound, analytics says volume-bound”, and reason about them, rather than silently letting the last writer win.
For anything beyond a single process, persist this state with checkpointing at
each step. Every transition (ROUTING → DELEGATED → SYNTHESIS) writes a checkpoint
to a durable store, Postgres, DynamoDB, Redis with persistence, whatever fits your
operational reality. This buys you three things: a long-running request survives a
process restart, you can replay a request deterministically when debugging, and you
get human-in-the-loop pause/resume for free (the request simply parks at a
checkpoint awaiting approval).

5. The shared tool layer and the namespace problem
Pulling tool logic out of individual agents into a shared layer is the obvious win: one orders client, one retry policy, one place that handles the schema migration. But two non-obvious problems appear at scale.
Tool name collisions. When you merge agents that were built independently, they
bring tools with overlapping names, two different get_status tools that mean
different things. If you flatten them into one namespace, the model will confuse
them. Namespace tools by their owning domain (orders.get_status,
fleet.get_status) and make the qualified name part of what the model sees.
Tool surface explosion. A worker agent that suddenly has access to every tool in the platform reasons worse, not better. More tools means a longer prompt, more plausible-but-wrong choices, and higher latency. The supervisor should hand each worker a scoped subset of tools relevant to its subtask. The forecast agent does not need write access to the labor system; don’t put the temptation in its context.
This is the agentic restatement of the principle of least privilege, and it is both a correctness lever and a security boundary. The blast radius of a hallucinated tool call is bounded by the tools the agent could see.
6. Synthesis: turning N contributions into one answer
Once workers report back, the supervisor synthesizes. This is not string
concatenation. The supervisor has the full set of Contribution objects and must
produce a single coherent answer, which means it must handle the case the whole
architecture exists for: the workers disagree.
Three strategies, in increasing sophistication:
-
Authority ordering. For a given question type, one agent is canonical. The forecast agent owns forward-looking numbers; the analytics agent owns actuals. Conflicts resolve by domain authority. Simple, predictable, and right surprisingly often.
-
Confidence-weighted. Each contribution carries a confidence; the supervisor weights accordingly and surfaces the disagreement when confidences are close. “Volume is the most likely driver, though staffing may also be a factor” is a more honest answer than false certainty.
-
Reflexive re-delegation. When contributions are irreconcilable, the supervisor issues a new subtask to break the tie, “both staffing and volume are implicated; pull the hourly breakdown to disambiguate.” This is where the supervisor’s ability to plan, not just route, pays off.
The thing to avoid is the silent merge, pasting both answers into the context and letting the model produce fluent text over the top. That produces confident prose that averages two contradictory facts, which is worse than either fact alone.
7. Observability: you cannot operate what you cannot trace
A multi-agent request is a distributed trace. One user turn fans out into a routing decision, several delegations, a dozen tool calls, and a synthesis step. When it goes wrong at 2 a.m., the question is always the same: where in that fan-out did it break? If your answer is “grep the logs of five services,” you have already lost.
Propagate a single request_id through every hop and emit a span per step, so a
trace reads top to bottom:
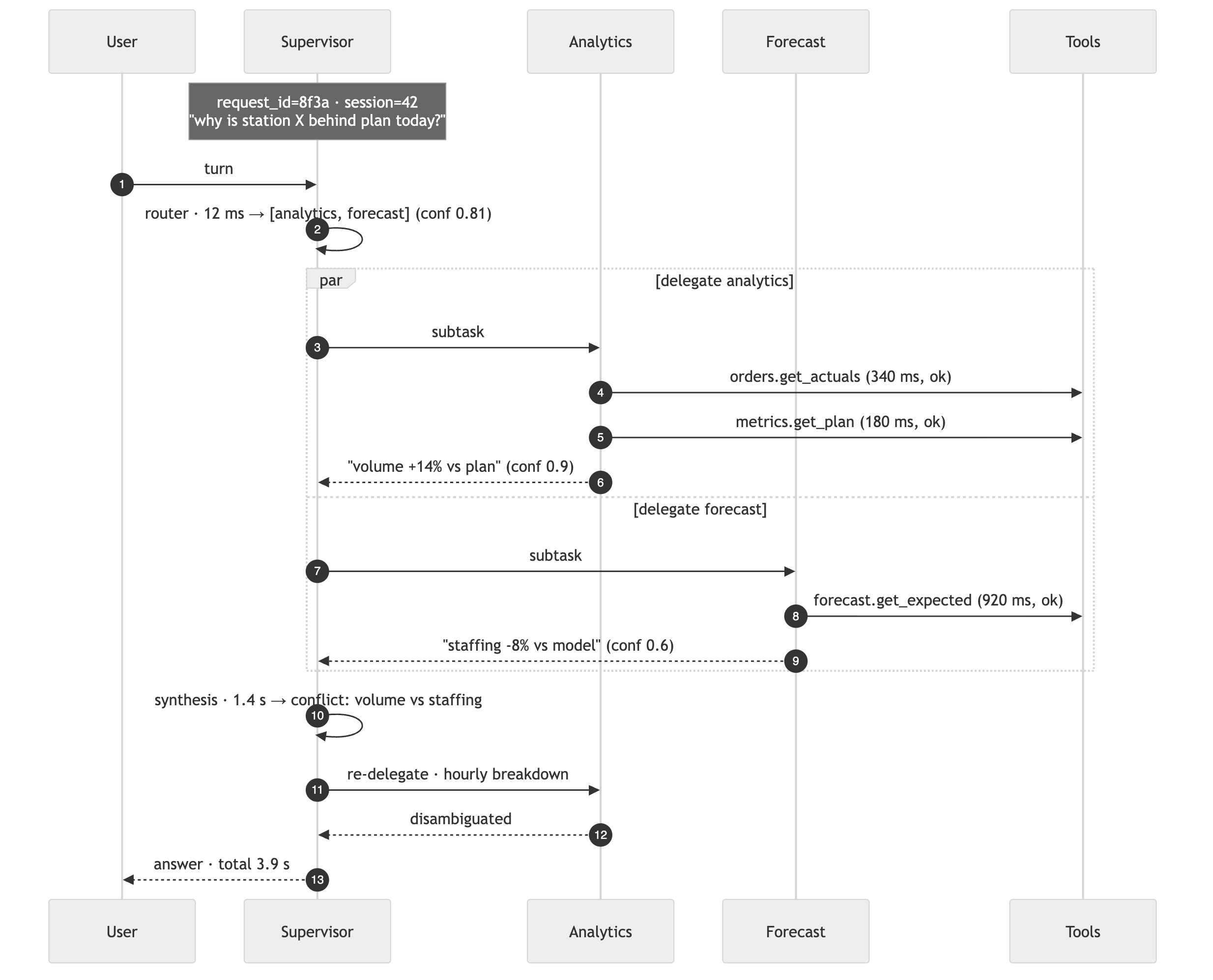
Beyond traces, instrument the dimensions that actually predict production health. The ones that earn their keep:
- Routing accuracy, sampled and human-labeled. The single most important number, because every downstream error inherits a routing error.
- Tool-call success rate, per tool. A tool quietly failing 5% of the time is a slow-bleeding source of wrong answers.
- Cache hit ratio across whatever caching tiers you run (see below).
- End-to-end and per-stage latency distributions, p50 and p99. Agent latency is heavy-tailed; the mean lies to you.
- Conflict rate at synthesis, how often workers disagree. A rising conflict rate is an early signal that two agents’ world models have drifted apart.
A useful rule of thumb from running these systems: budget on the order of 20+ metrics per agent system. That sounds like a lot until the first incident, when each one is the difference between a five-minute diagnosis and a five-hour one.
8. Latency: where the seconds hide, and how to get them back
Agent systems are slow by default because LLM calls dominate the critical path, and a supervisor can add latency: it inserts a routing hop and a synthesis hop around the real work. Three levers consistently move the number.
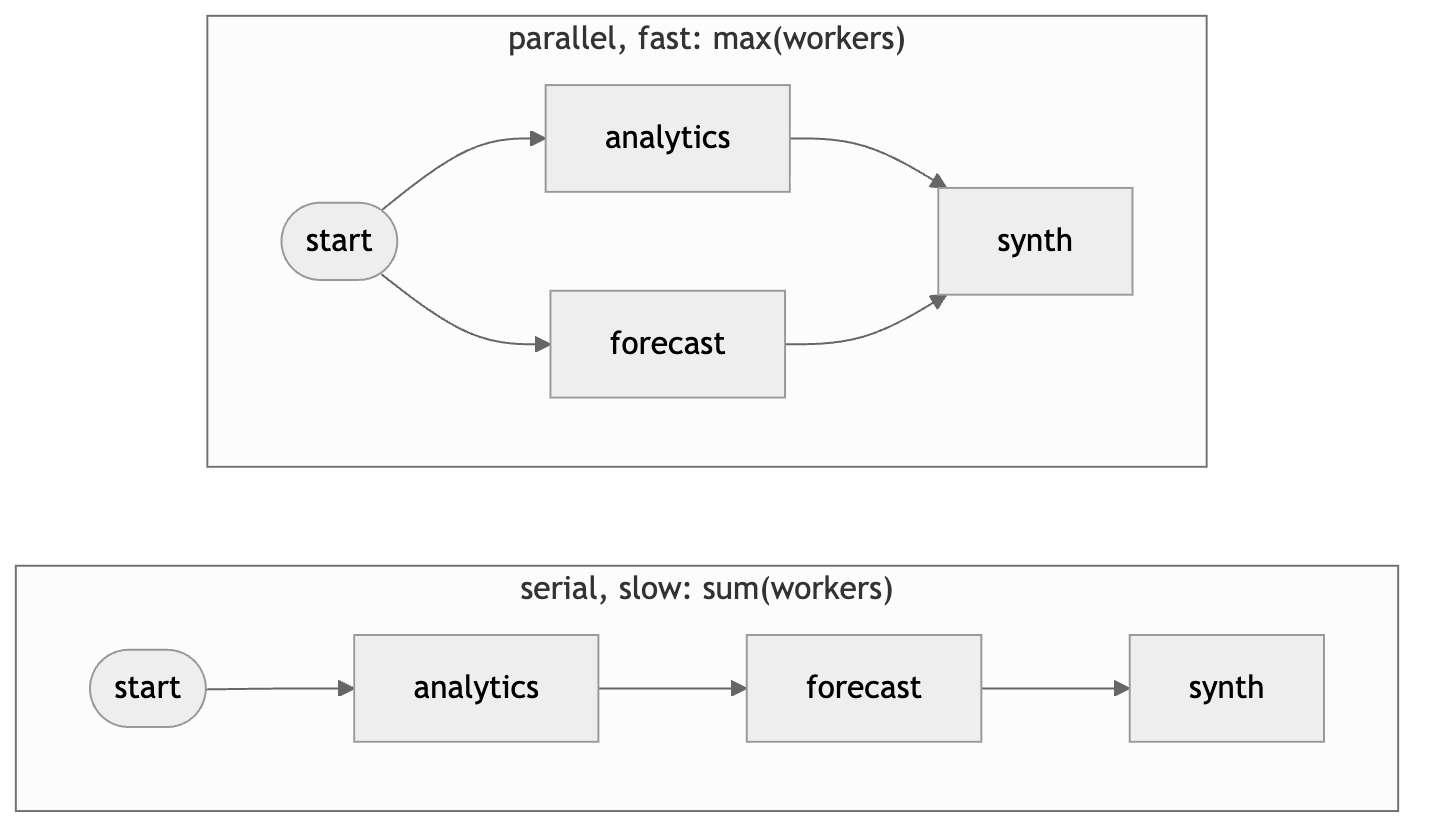
Parallelize independent delegations. If the router selected the analytics and
forecast agents and their subtasks don’t depend on each other, run them
concurrently. The supervisor’s structure makes this natural: it holds the plan, so
it knows which subtasks are independent. The end-to-end latency becomes
max(workers) plus overhead, not sum(workers).
Cache in tiers, because the cost structure is tiered. Not all repeated work is equal, so cache it at the level that matches its volatility:
- Tier 1: exact response cache. Identical query + scope +
as_of→ return the prior answer. Microseconds. Catches the genuinely repeated questions. - Tier 2: tool / retrieval cache. The underlying data (a metrics snapshot, a graph traversal) keyed by parameters and time bucket. Survives across different questions that touch the same data.
- Tier 3: semantic cache. Embed the query and serve a prior answer when a near-duplicate exists above a similarity threshold. Powerful but the riskiest: set the threshold conservatively, because a false hit serves a wrong answer, not a slow one.
Layering these can move a cold-path request that takes well over a minute down into the low-teens of seconds, and that latency cut is usually what flips a system from “demoed once” to “used daily.” Adoption follows responsiveness more than it follows capability.
Stream the synthesis. Even when the work is irreducibly slow, stream tokens as the supervisor produces them. Perceived latency is a real metric; the user who sees words appear at second two is more patient than the one staring at a spinner until second twelve.
9. Failure handling: the supervisor as a fault boundary
A worker will fail: a tool times out, a model returns malformed JSON, a downstream service sheds load. In a peer topology this failure is the user’s problem. In a supervisor topology it is the supervisor’s problem, which is exactly where you want it, because the supervisor has the context to degrade gracefully.
- Partial answers beat no answers. If the forecast agent times out but analytics succeeded, synthesize what you have and say what’s missing: “Here’s the actuals picture; the forecast comparison is unavailable right now.” A scoped, honest answer is more useful than a 500.
- Bound the worker. Every delegation runs under a timeout and a retry budget the supervisor sets. A worker cannot hang the whole request, because the supervisor owns the clock.
- Circuit-break flaky workers. If an agent’s tool is failing consistently, the supervisor should stop routing to it and fall back, rather than burning the latency budget on calls that will fail.
- Idempotency via the request_id. Because state is checkpointed and keyed by
request_id, a retried delegation can be made idempotent, you don’t double-apply a side effect on replay.
The mental model: the supervisor is a bulkhead. One worker’s failure is contained to a degraded contribution, not a failed request.
10. Build vs. buy, honestly
You do not have to write the supervisor loop, checkpointer, and router from scratch.
Frameworks like LangGraph’s StateGraph, AutoGen’s group chat, Strands, and
Bedrock’s multi-agent workflows implement these primitives. The honest evaluation axes,
having made this call in production:
- Traceability. Can you reconstruct a request end-to-end out of the box, or are you bolting on observability later? This dominates operational cost.
- State persistence. Is checkpointing first-class and pluggable to your durable store, or in-memory only?
- Tool routing & scoping. How much friction to give different workers different tool subsets?
- Latency overhead. Every framework adds some. Measure it on your workload, not the README’s benchmark.
- Long-term maintainability & lock-in. How hard is it to swap the model, the store, or the framework itself in eighteen months?
A structured evaluation against your constraints, not a feature-count comparison, is what separates a choice you’ll defend in a year from one you’ll be migrating off. And whatever you choose, the pattern in this article outlives the framework: when the next one ships, you’ll port the same supervisor, the same typed state, the same tiered router.
11. When you do not need a supervisor
Architecture writing tends toward “always do the complex thing.” So, plainly: if you have one agent, you do not need a supervisor; you need a good agent. If your two agents serve genuinely disjoint domains that never appear in the same conversation, a thin deterministic router in front of them is enough; the supervisor’s planning and synthesis machinery is dead weight.
The supervisor earns its complexity at a specific threshold: when requests routinely span multiple agents, when those agents can disagree, and when you need a single observable, recoverable record of what happened. Below that threshold it is over-engineering. Above it, its absence is the thing waking you up at night.
Closing
The progression from “some agents” to “an agent platform” is not about having smarter agents. It is about introducing a component that owns the request: that plans, routes deterministically where it can and probabilistically where it must, holds the authoritative state, scopes each worker’s power, synthesizes conflicting inputs into one honest answer, and leaves a single trace behind. That component is the supervisor, and getting it right is the difference between a fleet of agents that fight each other and a platform that compounds.
The pattern is old: coordinators, single-writer logs, bulkheads, least privilege. What’s new is applying it to workers that reason probabilistically. Treat the supervisor as distributed-systems engineering with an LLM in the loop, not as prompt engineering with extra steps, and the system will hold up under the load you eventually put on it.
Next in this series: designing the typed state object and checkpointing layer that makes a supervisor recoverable, including the late-arriving-data trap that breaks naive “what does today mean” logic.
Written by Gautham Rajendiran, Senior Software Engineer working on agent platforms and distributed data infrastructure. Opinions are drawn from production experience and are my own.